【AWS】AWS CLIでテンプレートがわからないときに役立つコマンド
はじめに
AWSコンソールで画面上でポチポチやるのは手間がかかるのとヒューマンエラーが発生してしまうことがあるため
できることならAWS CLIでやっていきたいと思うことがあります。
その際に --cli-input-json というオプションがありますが
実際にどのように作ればいいのかわからないことがあり、それを確認する方法をメモします。
コマンド
例えば「ECSのクラスターを確認する」とした場合 describe-clusters を実行するとします。
aws ecs describe-clusters \
--cluster MyCluster
しかし、コマンドが長くなることもあるのため別ファイルとして実行したい場合もあります。
その際は以下のようなコマンドを実行します。
aws ecs describe-clusters \
--cli-input-json file//./input.json
JSONファイルを正常動作するように記載しないと「Invalid JSON received」と表示されてしまいます。
そのため、JSONファイルの雛形を出力します。
aws ecs describe-clusters --generate-cli-skeleton
そうすると
{ "clusters": [ "" ], "include": [ "ATTACHMENTS" ] }
と出力されるため、これで必要な項目を入れて実行すれば「自分が入力したところに間違いがありそうだ」ということがわかってきます。
参考
【WAF】AWS WAFのCloudWatch Logsの名称は決まっているため気をつける
はじめに
業務でAWS WAFを使うことになりBot Controlを使うなどして
悪意あるアクセスでないか制御することになりました。
CloudWatch Metricsで集計しようとしたところ、まずは「CloudWatch Logs」にログを溜めないといけないのでそのやり方でハマったのでメモします。
やり方
参考ページにもあるが aws-waf-logs- で始まる必要があるということです。
例えばサービス名が ec-site だった場合 aws-waf-logs-ec-site とするのが良さそうです。
最初わからず適当に名前をつけても選択肢に出てこず悩んでしまいました。
参考
Amazon CloudWatch Logs による AWS WAF ログの分析 | Amazon Web Services ブログ
【Spark】ローカルでSparkをインストールしてみる
はじめに
半年ぐらいの業務でAWS Glueを使ったETLをやっていました。
しかし、Sparkの知識が足りず「Pysparkの関数ってどうやって使うの?」ということが多々あったため
Pysparkをローカルで動作できる環境を作ってみました。
環境
- macOS Monterey
前提条件
- Homebrewのコマンドが実行できること
やりかた
brew install openjdk@11 brew install apache-spark brew install python
以下のように起動すれば確認できるようになります。
Python 3.10.6 (main, Aug 11 2022, 13:49:25) [Clang 13.1.6 (clang-1316.0.21.2.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/09/06 08:57:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Python version 3.10.6 (main, Aug 11 2022 13:49:25)
Spark context Web UI available at http://192.168.1.62:4040
Spark context available as 'sc' (master = local[*], app id = local-1662422250363).
SparkSession available as 'spark'.
>>>
まとめ
これでPysparkを使って関数確認できるようになりました。
参考
【Glue】Glueを使い始めて知った単語などまとめ
はじめに
最近、サーバーサイドだけでなくデータ基盤も作る機会がありました。
サービスの成熟度や規模を検討した結果 AWS Glue(以下、Glue) を採用しました。
そこでGlueを名前だけ知っていた筆者が本番で使えるまでになり覚えた単語などをメモします。
前提条件
- Glueは使ったことがなく名前だけ知っている
- サーバーサイドエンジニアとして業務をしたことがある
単語一覧
AWS Glueとは
完全マネージド型 ETL (抽出、変換、ロード) サービス
データカタログとは
データストア(抽出元のテーブルなど)から自動的に作成されたメタデータ定義はデータカタログと呼ばれます。さらに、ユーザ自身がら編集することも可能です。
Glueクローラーとは
クローラは指定したデータストアを調べて、データカタログに登録してくれます。定期実行をする事で、スキーマやパーティションの定期的な自動更新も可能です。
なお、Glueの機能がわからなかったころ手動でデータカタログを作っていました。
これを実行することにより自動でデータカタログを作成することができます。
Glue Jobとは
ジョブは、AWS Glue で抽出、変換、ロード (ETL) 作業を実行するビジネスロジックで構成されます。
ジョブを開始すると、AWS Glue はソースからデータを抽出し、そのデータを変換してターゲット内にロードするためのスクリプトを実行します。
Python, Scalaで記述することができるようです。
今回、私はPythonでジョブをコーディングしました。
Glue Studioとは
今までGlue Jobは各言語でコーディングをしなければならなかったが、Glue Jobをノーコーディングで作成できるGUIです。
サンプルのインプットデータがあればGUI上で実行して動作確認もできます。
まとめ
EC2, ECS, RDSなどに比べるとかなりとっつきにくいサービスであるため、私も最初かなり戸惑いました。1つずつやっていき理解度を深めていきます。
参考
【Glue】【Glue Studio】なぜクローラーを使わずにデータカタログが作れるのか調べてみた
はじめに
普段の業務はバックエンドエンジニアなのだが、最近になって データ基盤 を作るようになりました。
データ基盤 と言うと大規模なものだと思われがちですが、新規サービスの基盤なので大きくはありません。
なので、まずは データを効率良く見える化 するためにデータ基盤作成初心者が Glue Studio を使ってノーコードで作成しました。
もともとのGlueの知識として
- ジョブ
- クローラー
- スケジュール
があることを認識していたのですが、クローラーを定義せずになぜ作れるのか?という疑問になったのでそのメモとなります。
環境
- AWS Glue ※記載時点での最新バージョン
前提条件
Glue Studioで下記のようなフローが作成されていること

調査
調べてみると以下の構文を使えば自動的にカタログが作れることがわかりました。
sink = glueContext.getSink(connection_type="s3", path="s3://path/to/data", enableUpdateCatalog=True, updateBehavior="UPDATE_IN_DATABASE", partitionKeys=["partition_key0", "partition_key1"]) sink.setFormat("<format>") sink.setCatalogInfo(catalogDatabase=<dst_db_name>, catalogTableName=<dst_tbl_name>) sink.writeFrame(last_transform)
特に重要なのが setCatalogInfo でこれを設定すれば作れるようです。
また、制限事項もあるようなので確認が必要です。
なお、ちょっとした小ネタですが
上記では partitionKeys を個別に設定しているが日本語文字列でもいけるらしく partitionKeys=["注文日"] という定義も可能でした。
ただし、日本語はやはりオススメしないため partitionKeys=["order_date"] とした方が良いです。
まとめ
ノーコードでできるように便利なものがあるのいいです。
ただ中身を知っていないと挙動がわからないままとなってしまうため
こういう調査は大事だと思いました。
参考
AWS Glue ETLジョブからの Data Catalog でのテーブルの作成、スキーマの更新、および新規パーティションの追加 - AWS Glue
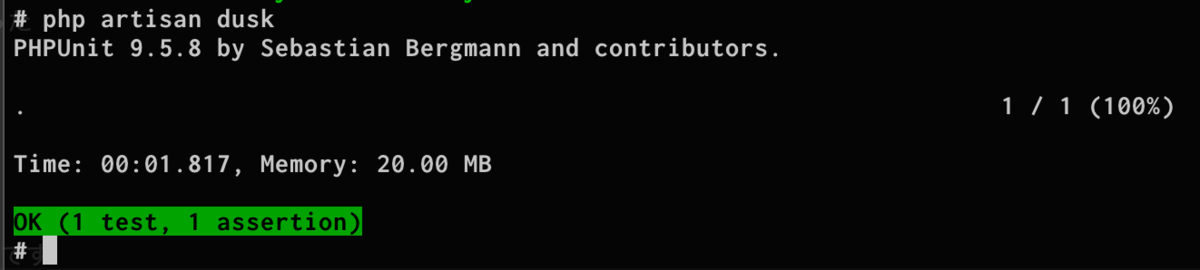
【PHP】【Laravel】laravel/duskで「php artisan dusk」 を実行すると「session not created」が出るときの対処法


【AWS】AWSのメルマガを購読して$25クレジットコードをもらおう
はじめに
ここ数ヶ月で「これは結構お得だな」と思ったのでブログで共有します。
最近は会社の福利厚生で一定額までAWS費用を負担してくれるところもありますがすべての会社がそうではありません。
しかし、少しでもAWSを無料で試す方法はないのか?と考えていたところ「$25クレジットコード」がもらえる方法がありましたので共有します。
AWSのウェブマガジン
2020年2月に創刊されたのが「builders.flash」です。
創刊についてのお知らせは以下の通りです。
ただし、ウェブマガジンだけではクレジットコードは受け取れません。
下記の画像を押して、メルマガ登録しないといけません。

やり方
メルマガを登録します。
builders.flash メールメンバー登録 | AWS
会社名など書きますが、会社に連絡は来たことありません。 特に利用目的では、「個人目的」にするといいと思います。
登録すると以下のようなメルマガが届きます。

記事の下に行くとキーワードとリンクがあり、リンクを押すと入力画面が出て入力していきます。

入力
条件は以下の通りのようです。
- builders.flash メールメンバーに登録している日本に所在地を持つお客様。
- AWS アカウントをお持ちのお客様(AWS アカウント ID の入力のない申請は無効となります。AWS アカウントの作成方法はこちら »)
- メールマガジンに記載の今月のキーワードを正しくご入力いただいていることが必要です。
- お一人様 1 回/月 の申請のみ有効です。同一のお客様からの複数の申請は全て無効となります。より多くのお客様へご提供するための条件となりますので、ご理解のほどお願い申し上げます。
- builders.flash がご提供するクレジットコードは、年間合計 10 回まで申請が可能です。(毎月のキーワードでの申請は各 1 回までとなります) 10 回を超える申請はクレジットコードの仕様に伴い、利用ができない場合がございます。あらかじめご了承ください。
※上記は入力画面から引用しました。
後は下記の通り入力するだけです。

入力してから翌月の第1週目になるとクーポンコードがメールアドレスに届きます。

後は下記の手順通りクーポンを入力するだけで完了です。
まとめ
AWSの書籍を買って「いざやってみよう!」と思ってもお金を取られるだけでモチベーションが下がります。 こういうのを使って上手に学習して仕事に繋げて行ければと考えています。
ちなみに自分が最近買ったAWSの書籍を貼っておきます。
コンテナ学習にはかなりオススメな一冊となっています。
![AWSコンテナ設計・構築[本格]入門](https://m.media-amazon.com/images/I/51m2BetgRZL._SL500_.jpg "AWSコンテナ設計・構築[本格]入門")